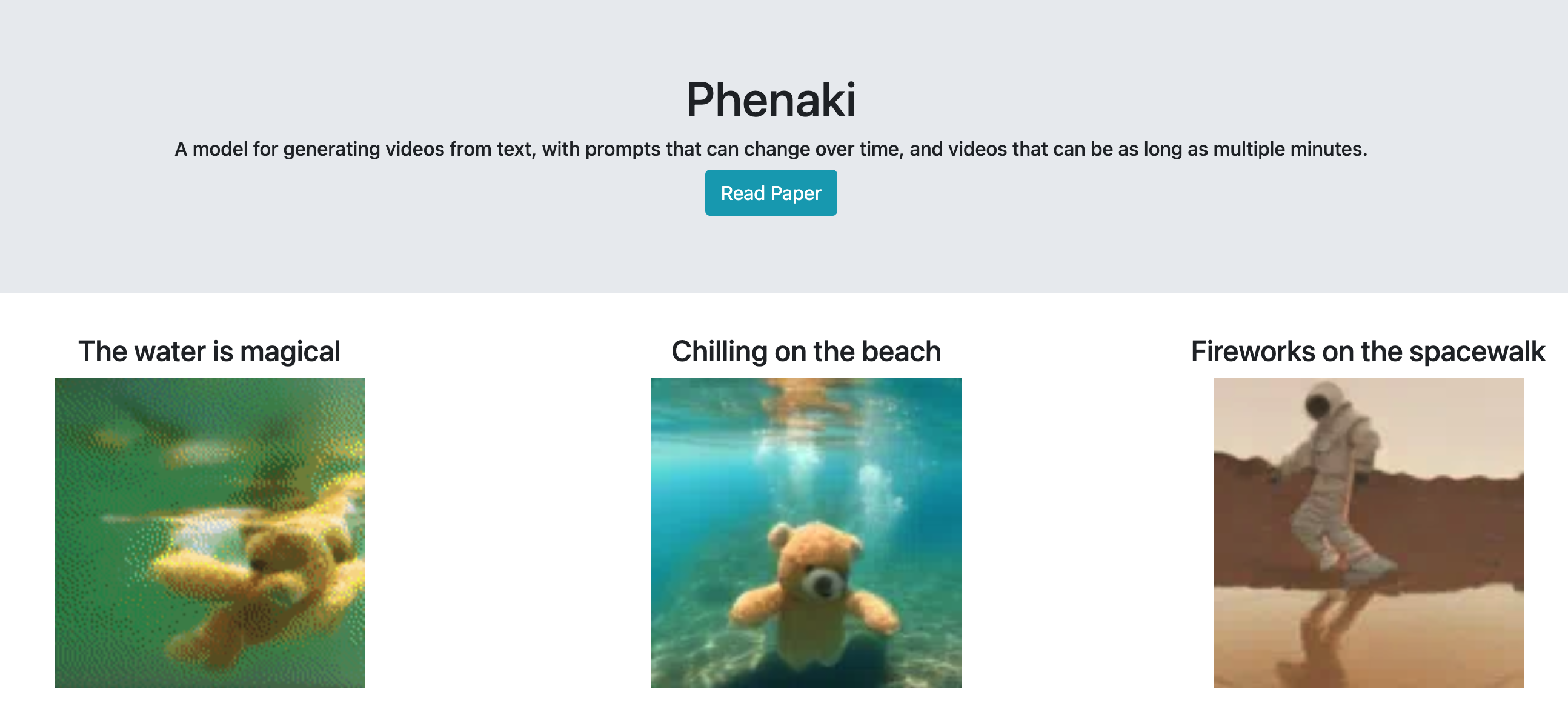
Phenaki是一个可以根据一系列文本提示生成逼真视频的模型。它通过将视频压缩为离散令牌的小表示来学习视频表达。模型使用时间上的因果注意力来生成视频令牌,并根据预先计算的文本令牌来条件生成视频。与之前的视频生成方法相比,Phenaki可以根据一系列提示(例如时间可变的文本或故事)生成任意长的视频。它的定位是在开放领域中生成视频。该模型还具有超出现有视频数据集范围的泛化能力。为了更好地满足用户需求,Phenaki还提供了交互式示例和其他应用场景。
需求人群:
适用于生成各种场景的视频,可以用于创意制作、广告、教育等领域。
产品特色:
根据文本生成逼真视频
支持时间可变的文本提示
可以生成任意长的视频
具有泛化能力
提供交互式示例
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
